
 زمان تقریبی مطالعه: 14 دقیقه
زمان تقریبی مطالعه: 14 دقیقهدر بخش اول مقالهی فرآیند مدیریت مشکل به تعریف چیستی و محدودهی عملکرد آن، ارتباط آن با دیگر فرآیندها، مزایای آن و همچنین شیوههای تجزیه و تحلیل مشکل پرداختیم. در بخش دوم، به بررسی گردش کار و وظایف در فرآیند مدیریت مشکل پرداخته، ورودیها، فرآوردهها و ارتباطات آن را تشریح میکنیم.
همچنین، در این مقاله، در مورد روند مدیریت اطلاعات در فرآیند مدیریت تغییر و نیز، KPIها، چالشها و عوامل موفقیت در مدیریت مشکل صحبت خواهیم کرد.
فعالیتهای فرآیندی، روشها و تکنیکها در مدیریت مشکل
در نموداری که در زیر مشاهده میکنید، روند یک فرآیند مدیریت مشکل و رفع آن، در حالت طبیعی، نشان داده شده است. در مورد تکتک مراحل روی نمودار در ادامه صحبت خواهیم کرد. البته در برخی مواقع باید مراحل دیگری نیز به این مراحل افزوده شوند. برای مثال، فعالیتهای مدیریت پیشگیرانه مشکلات میتواند دادههای جدیدی به این نمودار اضافه کند. (در مورد مدیریت پیشگیرانه و واکنشی در فرآیند مدیریت مشکل در بخش اول مقالهی فرآیند مدیریت مشکل صحبت کردیم. در ادامه نیز، این بحث را مفصلتر ادامه خواهیم داد.)
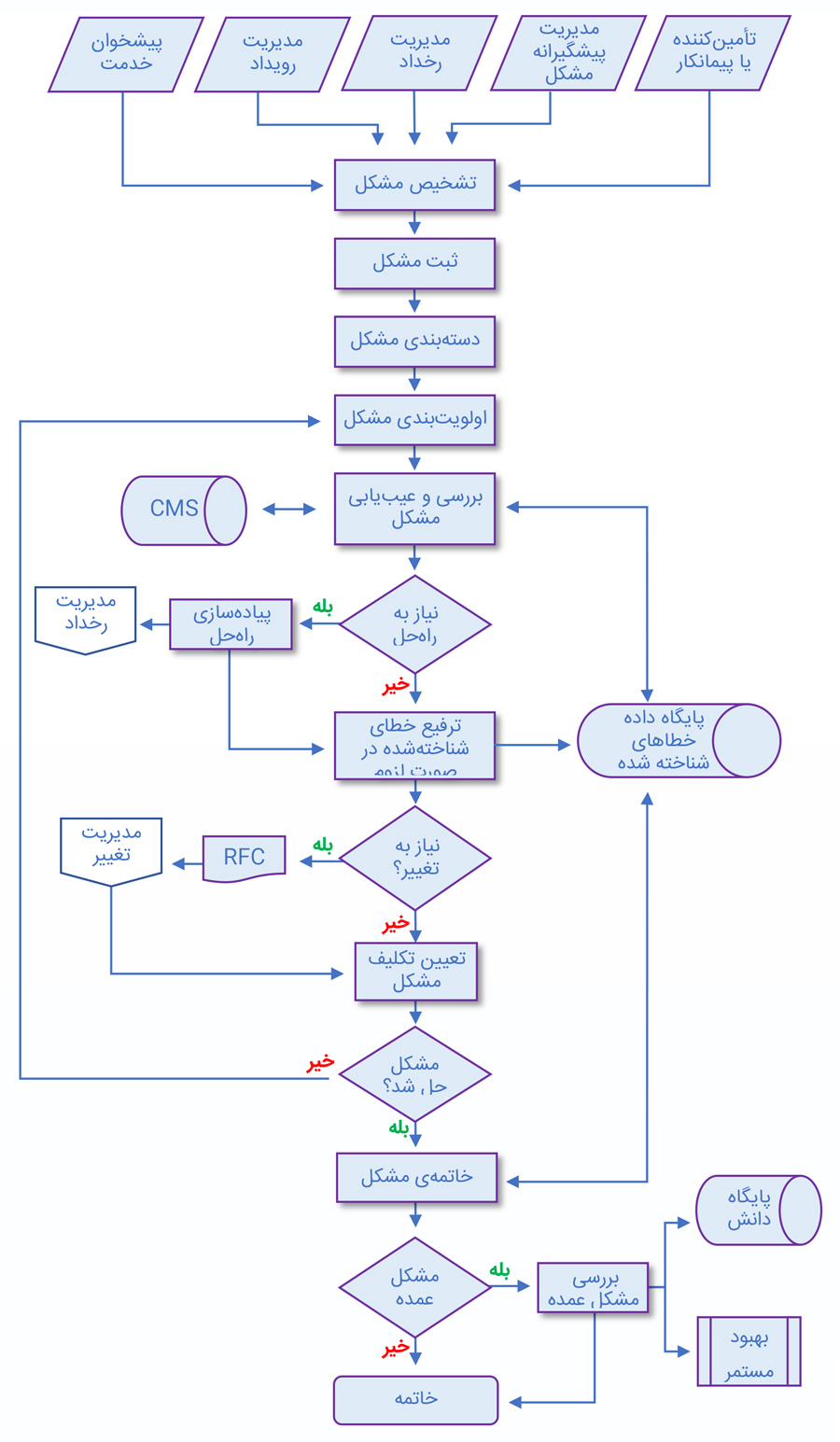
تشخیص مشکل
در همهی سازمانها، روشهای گوناگونی برای تشخیص مشکلات وجود دارد. این روشها به دو بخش مدیریت پیشگیرانه و واکنشی تقسیم میشوند:
روشهای تشخیص مشکل در مدیریت واکنشی مشکلات
- با تشخیص یا مفروض کردن علت یک یا چند رخداد توسط پیشخوان خدمت، یک مشکل ثبت میشود. پیشخوان ممکن است رخداد را رفع کرده باشد، ولی چون دلیل قطعی آن مشخص نشده است و احتمال تکرار رخداد میرود، مشکل را ثبت کرده است تا دلیل ریشهای مشکل شناسایی و رفع شود. حتی ممکن است از ابتدا مشخص شود که مشکل بزرگی وجود دارد که موجب بروز رخداد یا رخدادهایی شده است، بنابراین یک مشکل ثبت شده است تا بدون هیچ وقفهای رفع شود.
- با تجزیه و تحلیل رخداد توسط تیم پشتیبانی فنی، یک مشکل ریشهای شناسایی شده یا احتمال وجود آن میرود.
- تشخیص خودکار یک خطا در نرمافزار یا زیرساخت با استفاده از سیستمهای خودکار هشدار وقوع رویداد و در نتیجه ثبت یک رخداد که میتواند نشان از وجود یک مشکل داشته باشد.
اعلان وجود یک مشکل توسط تأمینکننده یا پیمانکار که نیاز است مرتفع شود.
روشهای تشخیص مشکل در مدیریت پیشگیرانه مشکلات
- تجزیه و تحلیل رخدادهایی که در نتایجشان، نیاز به ثبت مشکل آورده شده است و خطاهای اساسی باید بیشتر بررسی شوند.
- پیگیری رخدادهای قدیمی برای تشخیص یک یا چند دلیل اساسی که باید رفع شود تا بتوان از تکرار آنها جلوگیری کرد. در این حالت، مشکل یک بار ثبت شده و دلیل یا عامل اصلی کشف شده است.
- در نتیجهی ثبت یک مشکل برای مشخص شدن اقدامات بهبودبخش پیش رو، فعالیتهایی به منظور افزایش کیفیت خدمت، در دستور کار قرار میگیرد.
- تحلیلهای منظم و مکرر رخدادها، برای تشخیص علل پیشامد آنها، باید در دستور کار باشد. این امر نیازمند دستهبندی دقیق و معنادار رخدادها و مشکلات و نیز گزارشهای منظمی از الگوها و مکانهای متداول وقوع رخدادهاست. گزارش ده مورد اول با امکان رصد فهرست رخدادها تا ردیفهای پائینتر، میتواند مفید باشد.
- جزئیات بیشتر در موردچگونگی برخورد با عوامل تشخیص دادهشده، مشمول بهبود مستمر خدمت میشود.
ثبت مشکل
صرفنظر از روش تشخیص، همهی جزئیات مربوط به مشکل باید ثبت شود تا دادهای بدون نقص در آرشیو ذخیره شود. این دادهها باید شامل زمان و تاریخ باشند تا بشود آنها را بهتر کنترل کرد.
رکوردهای مشکل باید به رخداد یا رخدادهایی که در ارتباط با آنها هستند نیز ارجاع شوند و تمام اطلاعات رخداد، برای مشکل هم باید ثبت شود. به دلیل تنوع موارد، نمیتوان به صورت دقیق بیان کرد. ولی برخی از این اطلاعات بدین شرح هستند:
- اطلاعات کاربر
- اطلاعات خدمت
- اطلاعات تجهیزات
- زمان و تاریخ
- اولویتبندی و دستهبندی
- شرح رخداد
- شماره رخداد یا سایر ارجاعات
- شرح اقدامات تشخیصی و راهحلهای انجامشده
دستهبندی مشکل
مشکلات هم باید به همان شیوهی رخدادها دستهبندی شوند (و پیشنهاد میشود از همان سیستم کدگذاری هم استفاده شود). در نتیجه، هر زمان که لازم باشد، میتوان به اطلاعات مشکلها دسترسی داشت. ضمن آنکه موجب هماهنگی بیشتر مشکلات و رخدادها میشود.
اولویتبندی مشکلات
اولویتبندی مشکلات نیز باید به همان شیوه و دستورالعملی باشد که برای اولویتبندی رخدادها بهکار گرفته شده است. تناوب و تأثیر رخدادهای مرتبط نیز باید ثبت شود.
اولویتبندی مشکلات باید در بخش شدت مشکلات نیز ثبت شود. «شدت» در اینجا به میزان جدیت مشکل از دیدگاه خدمت یا مشتری و همچنین از منظر زیرساختی اشاره دارد. برای درک میزان شدت مشکل، میزان پرسشهای زیر را در مورد آن مطرح کرد:
- سیستم میتواند بازیابی شود یا نیاز به جایگزینی دارد؟
- چقدر هزینهبر خواهد بود؟
- چه تعداد نیروی انسانی و با چه تخصصی برای حل این مشکل مورد نیاز است؟
- حل این مشکل چقدر زمان خواهد برد؟
- مشکل چقدر گسترده است؟ (برای مثال، چه تعداد CI درگیر این مشکل شده است؟)
بررسی مشکل و عیبیابی
در این مرحله، برای رفع علت اصلی مشکل، باید عیبیابی صورت گیرد. سرعت و ماهیت این عیبیابی، بسته به تأثیر، شدت و فوریت مشکل متفاوت خواهد بود. اما سطح مناسبی از منابع و تخصصها با توجه به سطح اولویت مشکل و اهداف مدنظر خدمت، باید به کار گرفته شود تا دلایل اصلی مشخص شوند.
برای تعیین سطح تأثیر و تشخیص نقطه دقیق خطا، باید از CMS استفاده شود. همچنین، پایگاه داده خطای شناختهشده (KEDB) باید در دسترس باشد و از روشهای تطابق مشکل (مانند جستوجوی کلمات کلیدی) استفاده شود تا اگر مشکل پیش از این نیز اتفاق افتاده باشد، دلیل آن مشخص شود.
معمولاً تست تکرار خطای اتفاق افتاده برای تشخیص آنچه رخ داده است و امتحان روشهای مختلف برای یافتن بهترین راهحل و با کمترین هزینه، بسیار مفید فایده خواهد بود. شاید بتوان این کار را در محیط تستی (که آینهای از محیط عملیاتی سیستم است) انجام داد، بدون آنکه تأثیری بر فعالیت کاربران داشته باشد.
راهکارهای موقت در فرآیند مدیریت مشکل
گاهی اوقات ممکن است برای رخدادهایی که به واسطهی یک مشکل به وجود آمدهاند، بتوان راهکارهای موقتی برای غلبه بر مشکلات پیدا کرد. برای مثال، ممکن است یک اصلاحیهی دستی را در قالب یک فایل ورودی ایجاد کرد که امکان اجرای یک برنامه مهیا شود و سیستم پرداخت راهاندازی شود. ولی فراموش نکنیم که حین اجرای این راهکار موقت، کار روی یافتن راهحل اصلی باید ادامه یابد. در این مثال، باید دلیل اصلی خراب شدن فایل در اولین مرحله مشخص و اصلاح شود تا از تکرار آن جلوگیری شود.
هنگامی که یک راهکار موقت پیدا شد، باز بودن پروندهی مشکل و ورود جزئیات همین راهکار موقت نیز، بسیار مهم است.
در بعضی مواقع، ممکن است راهکارهای موقت متعددی برای یک مشکل وجود داشته باشد. در جریان تحقیق و عیبیابی مشکل، ممکن است یک سری بهبودهایی وجود داشته باشند که مشکل را حل نمیکنند، اما میتوانند موجب بهبود راهکارهای موقت موجود شوند.
اینها میتوانند به عنوان یک راهکار موقت موفق که موجب کاهش تأثیرات آیندهی رخدادهای مرتبط شده است، سطح اولویت مشکل را نیز تغییر دهند. این کاهش تأثیرات میتواند در قالب کاهش احتمال وقوع یا بهبود سرعت حل آنها باشد.
مشخص کردن خطای شناختهشده
خطای شناختهشده، با عنوان یک مشکل با دلیل اصلی و راهکار موقت ثبتشده، تعریف میشود. خطای شناختهشده باید مشخصکنندهی مشکل و اسناد مربوط به محتوای اقدامات مورد نیاز برای رفع مشکل، دلایل اصلی آن و راهکارهای موقت باشد. همهی خطاهای شناختهشده باید در KEDB ذخیره شوند.
به محض تکمیل مراحل تشخیص و بهویژه هنگامی که راهکار موقت کشف شد (حتی اگر هنوز راهحل اصلی کشف نشده باشد) باید خطای شناختهشده در سیستم ثبت شده و در KEDB قرار گیرد تا اگر رخداد یا مشکل مرتبطی اتفاق افتاد، سریعتر شناسایی شده و خدمت بازیابی شود. در بعضی مواقع ممکن است یک خطای شناختهشده را حتی قبل از تکمیل فرآیندها، حتی قبل از اینکه مراحل تشخیص کامل شود یا یک راهکار موقت کشف شود، در سیستم ثبت کنیم. این ممکن است برای تشخیص دلیل اصلی یا آدرسدهی راهکار موقت تأییدنشده مورد استفاده قرار گیرد. با این حال، نمیتوان با اطمینان تعیین کرد که چه زمانی باید خطای مشخصشده ثبت شود. در واقع، در اولین زمانِ ممکن که میتواند مورد استفاده قرار گیرد، باید ثبت شود.
راهحل مشکل
هنگامی که دلیل اصلی کشف شد و راهحلی برای رفع آن تدوین شد، باید به منظور حل مشکل به کار گرفته شود. درواقع، باید مطمئن شد که این راهحل، خود مسبب مشکلات بعدی نمیشود. اگر مستلزم تغییر عملکردهاست، باید RFC ثبت شده و پیش از اجرای راهحل، مجوز آن صادر شود. اگر مشکل بسیار جدی است و همسو با اهداف کسب و کار، باید به صورت اورژانسی حل شود، میتوان یک RFC اورژانسی ثبت کرد. راهحل باید هنگامی اجرا شود که مجوز تغییرات صادر شده و برنامهریزی لازم صورت پذیرد. در عین حال، باید برای کمک به حل سریعتر رخدادها یا مشکلات احتمالی پیش رو، از KEDB نیز استفاده شود.
ممکن است در برخی مواقع، مشکلاتی وجود داشته باشند که نتوان راهحل را برای آنها به کار برد (مانند هنگامی که تأثیر مشکل بسیار کم است، ولی هزینهی حل آن بالاست). در چنین مواقعی، ممکن است تصمیم بر بسته شدن مشکل گرفته شود، ولی یک راهکار موقت تشریح شود تا هنگام تکرار آن، سریعتر تشخیص داده شده و حل شود. توجه کنید که مشکلات باز را با استفاده از نشانهایی، مشخص کنید تا مجدداً در منابع مورد نیاز محاسبه نشده و از کارهای تکراری جلوگیری شود.
گاهی اوقات، ممکن است راهکارهای موقت اثرات مشکل را تعدیل کنند، بدون آن که راهحل نهایی پیدا شود. در این حالت، مشکل باید بر اساس تأثیر راهکار موقت مجدداً اولویتبندی شود و فعالیتهای تشخیص و عیبیابی ادامه یابد.
خاتمهی مشکل
هنگامی که راهحل نهایی اجرا شد، مشکل باید به صورت معمول بسته شود؛ همینطور هر رخداد مرتبطی که هنوز باز است. پس از آن، باید با بررسی محتوای رکورد مشکل، مطمئن شویم که همهی توضیحات و سوابق ثبت شده و در صورت نیاز، به روزرسانی شود.
وضعیت تمام مشکلات شناختهشدهی مرتبط باید بهروزرسانی شود تا نشاندهندهی اجرای راهحل نهایی باشند.
بازبینی مشکل اساسی
پس از هر مشکل اساسی (که طبق اولویتبندیهای سازمان تعریف میشود) و هنگامی که اتفاقات هنوز از خاطرمان نرفته است، باید یک فرآیند بازبینی انجام شود تا نکات آموزندهی آن، برای استفاده در آینده، استخراج شود. در این فرآیند، موارد زیر باید بررسی شوند:
- کارهایی که به طور صحیح، انجام شد.
- کارهایی که اشتباه انجام شد.
- کدام کار میتواند در آینده بهتر انجام شود.
- چطور میتوان از تکرار آن جلوگیری کرد؟
- جاهایی که مسئولیت شخص ثالث وجود دارد و جاهایی که فعالیتهای پیگیری مورد نیاز است.
چنین بازبینیهایی میتواند به عنوان بخشی از فعالیتهای ارتقای آموزش و آگاهی توسط بخش پشتیبانی مورد استفاده قرار گیرد. تمام نکات استخراجشده باید در قالب دستورالعملهای کاری، اصول تشخیصی، خطاهای شناختهشده یا سایر روشهای مقتضی، مستند شوند. مدیر مشکل وظیفه دارد این نکات را بررسی کرده و هر گونه اقدامات مرتبط را مستند کند. بازبینی مشکلات اساسی همچنین میتواند مرجع مدیریت پیشگیرانهی مشکل باشد و برای شناسایی دلایل اصلی ، در آینده مورد استفاده قرار گیرد.
دانش کسبشده از این بازبینی، باید در جلسات بازبینی خدمت با کاربران به اشتراک گذاشته شده و فعالیتهای برنامهریزی شده برای جلوگیری از تکرار مجدد مشکلات اساسی، تشریح شود. در نتیجهی این اقدامات، رضایت کاربران افزایش پیدا کرده و مدیران سازمان اطمینان مییابند که مدیریت خدمت در قبال رخدادهای اساسی مسئولیتپذیر بوده و فعالیتهایی را در راستای جلوگیری از تکرار آنها به کار بسته است.
ثبتکنندهها، ورودیها، خروجیها
ثبتکنندهها
با مدیریت واکنشی مشکلات، بیشتر مشکلاتِ ثبتشده در مورد چگونگی مواجهه با یک یا چند رخداد هستند و اکثراً توسط بخش پشتیبانی ثبت میشوند. سایر مشکلات ثبتشده و سوابق مشکلات شناختهشده، ممکن است در مراحل تست ثبت شوند. بهخصوص مراحل آخر آن، مانند نسخه/تست پذیرش کاربر (UAT)، اگر حتی با وجود برخی خطاها، تصمیم بر انتشار گرفته شود. ارائهدهندگان ممکن است نیاز به ثبت مشکل در رابطه با خطاهای بالقوه یا کمبودهای شناختهشده در محصولات یا خدماتشان داشته باشند (مانند هشداری در رابطه با استفاده از یک CI خاص و ثبت یک مشکل برای تشخیص آن CI در زیرساخت IT سازمان، توسط کارکنان بخش فنی).
با مدیریت پیشگیرانهی مشکلات، مشکلات میتوانند در جریان بازبینی سوابق رخدادها با شناسایی الگو و روشهای رخدادها ثبت شوند. بازبینی سایر منابع نظیر اطلاعات کاربری، ارتباطات کاربری یا اطلاعات رویدادها نیز میتواند منجر به تشخیص یک مشکل اساسی و ثبت پیشگیرانهی یک مشکل شود.
ورودیهای مدیریت مشکل
موارد زیر، نمونههایی از ورودیهای مدیریت مشکل هستند:
- سوابق رخدادهایی که منجر به فعالیتهای مدیریت مشکل شدهاند.
- گزارش رخدادها و سوابقی که برای پشتیبانی پیشگیرانه مشکلات مورد استفاده قرار میگیرد.
- اطلاعات CIها و وضعیت آنها
- ارتباطات و بازخوردهای رخدادها و علائم آنها
- ارتباطات و بازخوردهای RFC ها و نسخههایی که انتشار یافته یا برای اجرا برنامهریزی شدهاند.
- ارتباطات رویدادهایی که از مدیریت رویداد منجر شدهاند.
- عملیات و اهداف سطح خدمت
- بازخورد کاربر از موفقیت یک راهحل و کیفیت کلی فعالیتهای مدیریت مشکل
- معیارهای مورد توافق برای اولویتبندی و سطحبندی مشکلات
- خروجیهای مدیریت ریسک و ارزیابی خطر
خروجیهای مدیریت مشکل
موارد زیر، نمونههایی از خروجیهای مدیریت مشکل هستند:
- مشکلات حلشده و اقداماتی که برای دستیابی به راهحل آنها منظور شده است.
- سوابق بهروز مدیریت مشکلات، شامل جزئیات اتفاق و تاریخچهی آن
- رکورد RFC ها برای حذف خطاهای زیرساختی
- راهکارهای موقت برای رخدادها
- گزارشهای مدیریت مشکل
- دستاوردها و توصیههای بهبوددهندهی استخراجشده از بازبینی مشکلات اساسی
روابط فرآیندی و کارکردی
در بخش اول مقالهی فرآیند مدیریت مشکل، به تفصیل در مورد رابطهی میان فرآیند مدیریت رخداد و مدیریت مشکل صحبت کردیم. در ادامه، به بررسی رابطهی این فرآیند با سایر فرآیندها در هر مرحله از چرخه عمر خدمت خواهیم پرداخت.
استراتژی خدمت
- مدیریت مالی برای خدمات IT: برآورد تأثیر راهحل یا راهکار موقت مطرح شده، همانند تجزیه و تحلیل عمق فاجعه. مدیریت مشکل، مدیریت اطلاعات هزینههای حل و جلوگیری مشکلات را نیز ممکن میسازد که به عنوان ورودی به سیستمهای مالی و حسابداری و محاسبهی هزینههای کل مالکیت استفاده میشود.
طراحی خدمت
- مدیریت دسترسپذیری: تعیین چگونگی کاهش قطعی سیستم و افزایش دسترسی آن از اهمیت بالایی برخوردار است. این امر رابطه تنگاتنگی با مدیریت مشکل دارد، بخصوص در حیطهی مدیریت پیشگیرانه. بخش عمدهای از اطلاعاتی که در مدیریت مشکل وجود دارد میتواند در مدیریت دسترسپذیری استفاده شود.
- مدیریت ظرفیت: بعضی از مشکلات نیازمند تشخیص با روشها و تیم مدیریت ظرفیت است، مانند مسائل مربوط به عملکرد. مدیریت ظرفیت، همچنین در ارزیابی اقدامات پیشگیرانه کمک میکند. مدیریت مشکل، مدیریت اطلاعات مرتبط با کیفیت تصمیماتی را که در خلال فرآیندهای برنامهریزی ظرفیت اتخاذ میشوند، ممکن میسازد.
- مدیریت تداوم خدمت IT: هنگامی که یک مشکل مهم حل نشده است و قبل از آن که تأثیری اساسی بر کسب و کار بگذارد، مدیریت مشکل به عنوان یک نقطه ورود به مدیریت تداوم خدمت IT عمل میکند.
- مدیریت سطح خدمات: وقوع رخدادها و مشکلات بر سطح خدمات ارائهشده که توسط SLM سنجیده میشود، اثر میگذارند. مدیریت مشکل به بهبود سطح خدمات کمک کرده و اطلاعات مدیریتی آن، به عنوان اطلاعات پایه در برخی از اجزای بازنگریهای SLA مورد استفاده قرار میگیرد.
انتقال خدمت
- مدیریت تغییر: مدیریت مشکل، اطمینان میدهد که تمام راهحلها و راهحلهای ضمنی که نیازمند تغییر در CI هستند، در RFC و از طریق مدیریت تغییر تأیید میشوند. مدیریت تغییر روند این تغییرات را پیگیری کرده و پیشنهاد مدیریت مشکل را نیز حفظ میکند. مدیریت مشکل، همچنین موقعیتهایی را که در پس تغییرات ناموفق به وجود میآید، حل و فصل میکند.
- مدیریت دارایی و پیکربندی: مدیریت مشکل با استفاده از CMS، به بررسی CIهای معیوب و تعیین تأثیر مشکلات و راهحلها میپردازد.
- مدیریت انتشار و استقرار: این فرآیند، مسئول استقرار حل مشکل در محیط زنده است. همچنین، اطمینان میدهد که خطاهای شناختهشده از محیط تولید KEDB به پایگاه داده عملیاتی خطاهای شناختهشده انتقال مییابد. مدیریت مشکل به حل مشکلاتی که در طول فرآیندهای انتشار اتفاق میافتد کمک میکند.
- مدیریت دانش: SKMS (سامانه مدیریت دانش خدمات) میتواند برای تعیین پایههای KEDB و نگهداشت یا یکپارچهسازی با سوابق مشکلات مورد استفاده قرار گیرد.
بهبود مستمر خدمت
- هفت گام به سوی بهبود مستمر: وقوع رخدادها و مشکلات، پایهای برای شناسایی فرصتهای بهبود خدمات و افزودن آنها به CSI، فراهم میکند. فعالیتهای مدیریت پیشگیرانه موجب شناسایی مشکلات اساسی شده و در نهایت، میتواند موجب افزایش کیفیت سرویس و رضایت کاربر نهایی شود.
مدیریت اطلاعات
اکثر اطلاعات استفاده شده در مدیریت مشکل، از منابع زیر به دست میآید:
سیستم مدیریت پیکربندی (Configuration Management System: CMS)
جزئیات تمام اجزای زیرساخت IT و روابط میان آنها در CMS نگهداری میشود. این اطلاعات میتواند به عنوان یک منبع باارزش در تشخیص مشکلات و ارزیابی اثرات آنها مورد استفاده قرار گیرد (برای مثال، هنگام از کار افتادن یک فضای ذخیرهسازی، چه اطلاعاتی در آن موجود بود؟ کدام خدمت ها از این اطلاعات استفاده میکردند؟ کدام کاربران از آن خدمتها بهره میبردند؟). همچنین با نگهداشت جزئیات اقدامات قبلی، میتوانید برای تشخیص اثرات یا نقاط ضعف بالقوه و به عنوان بخشی کلیدی از مدیریت پیشگیرانه مشکلات، مورد استفاده قرار دهید.
پایگاه داده خطای شناختهشده (Known Error Data Base: KEDB)
هدف از KEDB، ذخیرهسازی دانش مربوط به رخدادها و مشکلات و چگونگی پیشامد آنهاست تا تشخیص و حل آنها در صورت تکرار، سادهتر و سریعتر باشد.
دادههای خطای شناختهشده باید شامل جزئیات ریزبینانه از عیوب و نشانههای پیشامد آن، به همراه اطلاعات دقیق هر راهکار موقت و قطعی را که منجر به بازیابی خدمت و حل مشکل شده است، باشد. شمارش رخداد نیز میتواند به منظور تعیین فرکانس هر رخدادی که مستمر تکرار میشود و بر اولویتها تأثیر میگذارد، مفید باشد.
باید توجه داشت که بسته به نوع کسب و کار، ممکن است برای بعضی از مشکلات، راهحل دائمی وجود نداشته باشد. برای مثال، اگر یک مشکل، مسبب قطعی مهمی نباشد و راهکار موقت موجود یا مزیت آن خدمت، در برابر هزینههای راهحل دائمی مشکل ناچیز باشد، ممکن است تصمیم بر تحمل مشکل گرفته شود. اگرچه باز هم با این وجود، تشخیص و تعیین یک راهکار موقت در سریعترین زمان ممکن، مطلوب خواهد بود که در این زمینه KEDB میتواند راهگشا باشد.
باید بتوان از هر دادهای که در پایگاه داده ذخیره میشود، سریع و دقیق استفاده کرد. مدیریت مشکل نیز باید با روشها و الگوریتمهای جستجو که در پایگاه داده مورد استفاده قرار گرفته، در انطباق کامل باشد. ضمن آنکه باید مطمئن باشیم که هنگامی که یک داده جدید در پایگاه داده افزوده میشود، معیارهای جستوجوی مربوطه در آن گنجانده شده است.
هنگام ورود اطلاعات باید دقت کافی داشته باشیم که از ورود دادههای تکراری جلوگیری کنیم (برای مثال، نباید مشکلی یکسانی با روشهای متفاوت در قالب رکوردهای مختلف ثبت شود). برای این منظور، مدیر مشکل باید تنها شخصی باشد که امکان ورود دادههای جدید را دارد. سایر اشخاص نیز میتوانند دادههای جدید را پیشنهاد دهند. اما در نهایت مدیر مشکل تصمیم میگیرد که آنها را در KEDB وارد کند.
در سازمانهای بزرگ که از یک KEDB استفاده میشود (استفاده از یک CDMB پیشنهاد میشود) و کارمندان بخش مدیریت مشکل در مکانهای مجزایی هستند، باید روشهایی به کار گرفت تا از رکوردهای تکراری در KEDB جلوگیری شود. این مورد میتواند با تعیین فقط یک فرد به عنوان مدیر مرکزی KEDB انجام شود.
در حین مراحل تشخیص یک مشکل و رخداد، باید از KEDB استفاده کرد تا روند حل، با سرعت بیشتری انجام شود و هنگام تشخیص یک مشکل جدید، باید در سریعترین زمان ممکن، داده جدید اضافه شود.
تمام کاربران پشتیبانی باید کاملاً آموزشدیده و با مزایای KEDB و روشهای بهرهگیری از آن آشنا باشند. ضمن آنکه آنها باید قطعاً امکان فراخوانی و استفاده از دادهها را نیز داشته باشند.
KEDB بخشی از CMS بوده و میتواند بخشی از یک (SKMS (Service Knowledge Management System بزرگتر باشد که در شکل زیر ترسیم شده است.
توجه داشته باشید که (SCMIS (Supplier Contract Management Information System برای سیستم مدیریت اطلاعات تأمینکنندهها و قراردادهاست.
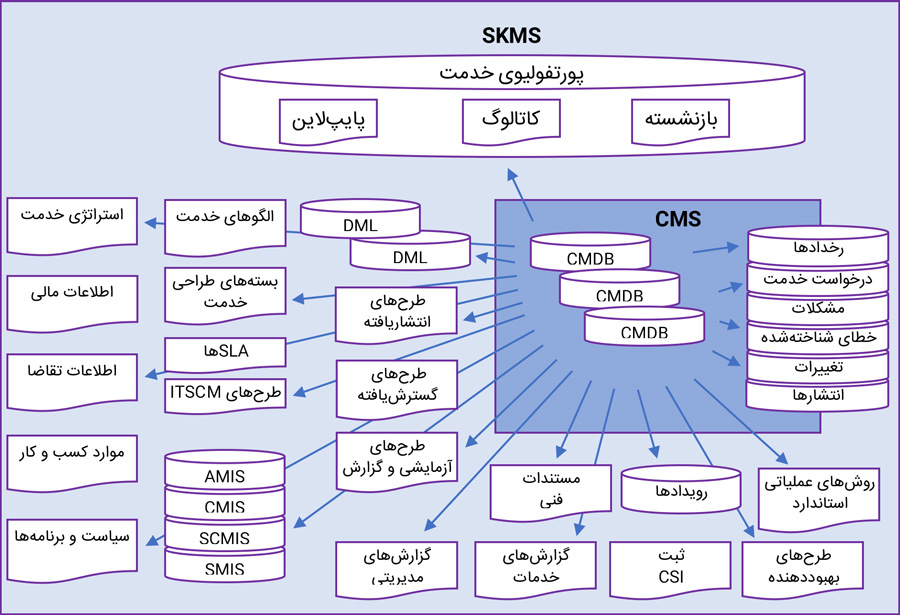
نمونهای از دادهها و اطلاعات در سیستم مدیریت دانش خدمت
عوامل حیاتی موفقیت و شاخصهای کلیدی عملکرد
فهرستی که در ادامه ارائه شده، شامل برخی نمونههای CSF (Critical Success Factors) برای مدیریت مشکل است. هر سازمان باید CSFهای منطبق با اهداف خود را برای فرآیندها تعیین کند. هر CSF نمونه توسط تعداد کمی از KPI ها دنبال میشود که آن CSF را پشتیبانی میکنند. این KPIها نباید بدون توجه دقیق، اتخاذ شوند. هر سازمان باید KPIهایی را توسعه دهد که با سطح بلوغ سازمان، CSFها و شرایط خاص آنها تطابق دارد. دستاوردها در برابر KPIها نیز باید مورد بررسی قرار گیرند تا فرصتهای بهبود مشخص شوند و در ثبت CSI و برای ارزیابی و اجرای احتمالی، وارد شوند.
CSF : به حداقل رسانی تأثیرات رخدادها بر کسب و کار که قابل جلوگیری نیستند.
- KPI: تعداد خطاهای شناختهشده که به KEDB افزوده شده است.
- KPI: درصد صحت KEDB (از حسابرسی پایگاه داده)
- KPI: درصد رخدادهایی که توسط پیشخوان خدمت بسته شدهاند، بدون آنکه به بخشهای دیگر پشتیبانی ارجاع داده شوند. (اغلب به عنوان «نقطه اول تماس» شناخته میشود)
- KPI: میانگین زمان حل رخداد برای آن دسته از رخدادهایی که به یک مشکل لینک شدهاند.
CSF: حفظ کیفیت خدمات فناوری اطلاعات با از بین بردن حوادث تکراری
- KPI: تعداد کلی مشکلات (به عنوان یک اقدام کنترلی)
- KPI: ابعاد مشکل فعلی که برای هر خدمت IT انباشت شده است، به عنوان یک اقدام کنترلی
- KPI: تعداد رخدادهای تکراری برای هر خدمت IT
CSF: ارائه کیفیت کلی و اقدامات حرفهای برای کنترل مشکلات، در راستای قابلیت اتکای کسبوکار به قابلیتهای IT
- KPI: تعداد مشکلات اساسی (باز شده، بستهشده و انباشتشده)
- KPI: درصد مشکلات اساسی که با موفقیت بازبینی شدهاند.
- KPI: درصد مشکلات اساسی که با موفقیت و در زمانِ خود بازبینی شدهاند.
- KPI: تعداد و درصد مشکلاتی که به طور صحیح دستهبندی شدهاند.
- KPI: انباشت مشکلات بزرگ و گرایش آنها (ثابت، کاهشی یا افزایشی)
- KPI: تعداد و درصد مشکلاتی که از زمان مدنظرشان بیشتر طول کشیدهاند.
- KPI: درصد مشکلاتی که در محدوده اهداف SLA حل شدهاند.
- KPI: هزینهی میانگین هر مشکل
طبقهبندی و ترتیبدهی به مشکلات بر اساس معیارهای قابل اندازهگیری مانند زمان، تأثیر، فوریت، تأثیر خدمت، مکان و اولویت و مقایسهی اینها با دورههای قبلی، بسیار مفید خواهد بود. این امر، امکان وارد کردن به CSI و سایر فرآیندهای پیگیری برای تشخیص مسائل، پیگیری مشکلات یا موقعیتهای دیگر را فراهم میکند.
چالشها و خطرات پیش روی فرآیند مدیریت مشکل
چالشها
برای یک مدیریت موفق مشکل، چالشهای زیر پیش روی ماست:
- یکی از وابستگیهای بسیار مهم مدیریت مشکلات، استقرار یک سیستم قدرتمند مدیریت رخداد است. این امر، اطمینان میدهد که مشکلات در سریعترین زمان ممکن شناسایی میشوند و این مانند بسیاری از کارها با پیشداوری همراه است. اطمینان از اینکه فرآیندهای این دو سیستم از رابط کاربری استاندارد و شیوههای کار مشترک بهره میبرند، چالشی مهم است.
- گاهی اوقات، مهارتها و قابلیتهای لازم برای کارمندانی که وظیفهی حل مشکل را برعهده دارند، برای اینکه بتوانند دلیل اصلی رخدادها را کشف کنند، تبدیل به یک چالش میشود. بسیاری از اوقات، کارمندان پشتیبانی بر اساس دلایل یا فعالیتهای قبلی، دلیل اصلی را شرح میدهند. روشهای شرح دادهشده میتواند برای کشف دلیل اصلی یک رخداد، مورد استفاده قرار گیرند. تمرکز روی این پرسش که «چرا این اتفاق افتاد؟» یا «چه کاری میتوان انجام داد که از اتفاق دوباره این رخداد جلوگیری کرد؟» نیز میتواند مفید باشد.
- اگر ابزارهایی که برای ثبت رخدادها استفاده میشود، متفاوت از ابزارهای ثبت مشکلات باشند، قابلیت ارتباط میان رخدادها و مشکلات، میتواند به یک چالش بدل شود. برخی مواقع ممکن است ابزارهای رخداد، بدون هیچ قابلیت دیگری، فقط برای رصد کردن مشکلات، وجود داشته باشند.
- قابلیت یکپارچهسازی فعالیتهای مدیریت مشکل با CMS در راستای تبیین روابط میان CIها و برای ارجاع به سوابق CI هنگام ارائه پشتیبانی
- اطمینان از اینکه مدیریت مشکل، قابلیت استفاده از همهی دانشها را داشته و منابع مدیریت پیکربندی و دارایی سرویس برای تحقیق و حل مشکلات، در دسترس است.
- اطمینان از اینکه، آموزش مداوم کارکنان فنی در هر دو زمینهی فنی مربوط به شغلشان و زمینه مفهوم خدماتی که از آنها پشتیبانی میکنند و نیز فرآیندهایی که استفاده میکنند، انجام میشود.
- توانایی برقراری یک رابطهی مناسب میان کارمندان لایهی دوم (و سوم) که روی فعالیتهای پشتیبانی مشکلات کار میکنند و کارمندان لایهی یک.
- اطمینان از اینکه تأثیرات مدنظر کسب و کار با کارمندانی که روی حل مشکلات فعالیت میکنند، به خوبی دریافت شده است.
خطرات
در واقع خطرات مدیریت مشکلات، شباهت زیادی با چالشهای آن دارد و به برخی از CSFهایی که در بالا اشاره شد، باز میگردد. این خطرات، شامل موارد زیر است:
- مدفون شدن زیر انبوهی از مشکلاتی که به دلیل ضعف در آموزش کارمندان، در زمان مورد قبول مدیریت نشدهاند.
- مشکلات در حال افزایش هستند و به دلیل ابزارهای پشتیبانی ناکافی برای تحقیق، پیشرفتی در آنها رخ نمیدهد.
- فقدان منابع اطلاعاتی کافی یا به موقع، به دلیل ابزارهای نامناسب یا ضعف در یکپارچهسازی.
- عدم آموزش صحیح کارمندان پشتیبانی، برای تحقیق دربارهی مشکلات، یافتن دلایل اساسی یا شناسایی اقدامات مناسب برای حذف خطاها.
- ناسازگاری در اهداف یا فعالیتها، به دلیل ارجاع ضعیف یا عدم ارجاع قراردادهای OLA.