
 زمان تقریبی مطالعه: 10 دقیقه
زمان تقریبی مطالعه: 10 دقیقهفرآیند مدیریت مشکل از فرآیندهای بالغ نظام مدیریت خدمات فناوری اطلاعات بهشمار میرود که از یک سو ارتباطی متناظر با فرآیند مدیریت رخداد (معمولاً از منظر دستهبندی، اولویتبندی، اثرگذاری و…) دارد و حلقهی واسط مدیـریت رخداد با فرآیند مدیـریت تغییر است و از سوی دیگر، ارتباطی تنگاتنگ با فرآیند مدیریت دانش دارد.
به بیان دیگر، پس از بروز یک رخداد، زمانی برای یک تغییر اقدام میکنیم، که علت ریشهای مشکل را شناسایی کرده باشیم. چراکه در غیر این صورت، احتمال هدررفت منابعی که صرف تغییر میکنیم، بسیار است.
به دلیل اهمیت و جایگاه فرآیند مدیریت مشکل در ساختار مدیریت خدمات فناوری اطلاعات، در بخش ابتدایی مقالهی حاضر، به بیان تعریف، اهداف، دستاوردهای استقرار این فرآیند، محدودهی عملکرد و سیاستهای پیشگیرانه و واکنشی در این فرآیند، و نوع ارتباط آن با سایر فرآیندهای مرتبط پرداختهایم و در ادامه، پرکاربردترین روشها و تکنیکهای تجزیه و تحلیل مشکل را که از نخستین گامها در فرآیند مدیریت مشکل است، بررسی کردهایم. در بخش بعدی مقاله، بحث را با اقدامات، فعالیتها، گردشهای کار و چالشهای این فرآیند به شکل مفصلتری ادامه خواهیم داد.
برای درک اهمیت فرآیند مدیریت مشکل، لازم است حداقل اِشرافی به مفهوم فرآیند مدیریت رخداد داشته باشید. به این منظور، پیشنهاد میکنیم قبل از ادامهی مقاله، حتماً ویدئوی آموزشی فرآیند مدیریت رخداد را ببینید.
تعریف
ITIL مشکل را اینگونه معرفی میکند: «دلیل اساسی یک یا تعدادی از رخدادها». اما فرآیند مدیریت مشکل درواقع فرآیند پیگیری چرخه حیات تمام مشکلات است.
هدف فرآیند مدیریت مشکل
هدف از فرآیند مدیریت مشکل چنان که بیان شد، مدیریت چرخه حیات تمام مشکلات، بر اساس فهرست شناسایی اولیهای است که از بررسیهای گسترده، مستندات و حذفیات احتمالی به دست آمده است.
فرآیند مدیریت مشکل به دنبال کاهش هرچه بیشتر اثرات نامطلوب رخدادها و مشکلات بر کسب و کاری است که دلیل آنها خطاهای اساسی در زیرساخت فناوری اطلاعات است. در نتیجه، هدف آن این است که از تکرار رخداد مرتبط با این خطاها جلوگیری کند. برای دستیابی به این هدف، فرآیند مدیریت مشکل به دنبال ریشههای مشکلات، مستندات و ارتباطات میان خطاهای شناختهشده و اقدامات اولیه برای تقویت یا اصلاح وضعیت است.
دستاوردهای فرآیند مدیریت مشکل
دستاوردهای فرآیند مدیریت مشکل را میتوان به سه بخش اساسی طبقهبندی کرد:
- جلوگیری از وقوع مشکلات و رخدادهای مربوطه
- ممانعت از وقوع دوبارهی رخدادهای تکراری
- کاهش هرچه بیشتر اثرات ناشی از رخدادهای ناگزیر
سیاستهای کلی
نمونههایی از سیاستهای کلی فرآیند مدیریت مشکل به شرح زیر است:
- مشکلات باید مجزا از رخدادها پیگیری شوند. در واقع، تفاوت فاحشی وجود دارد میان بسیاری از فعالیتهای فرآیند مدیریت مشکل که پیشگیرانه هستند و فعالیتهای مدیریت رخداد که اغلب واکنشی هستند. بنابراین، سیستمها نیز میبایست این دو را جدا از هم پیگیری کنند.
- تمام مشکلات باید در یک سیستم مدیریتی واحد، ذخیره و مدیریت شوند. این امر، یک سیستم واحد برای اطلاعات مشکلات فراهم میکند که دسترسی سادهتری را برای گزارشگیری و تحقیقات، به ارمغان میآورد. سیستمهای پشتیبانی نیز باید با رابطهای کاربری که اطلاعات مرتبط با مشکلات را ارائه میدهند، کاملاً یکپارچه باشند.
- تمام مشکلات باید در یک سیستم طبقهبندی استاندارد که در محدوده کسب و کار تعریف شده، قرار گیرند. این امر نهتنها موجب دسترسی سریعتر به اطلاعات خواهد شد، بلکه پشتیبانی بهتری را برای مدیریت مشکلات و فعالیتهای پیشگیرانه فراهم میکند. ضمن آنکه مجموعهای از طبقهبندیها با روابط میان آنها شکل خواهد گرفت.
ارتباط فرآیند مدیریت مشکل با سایر فرآیندها
فرآیند مدیریت مشکل دربردارندهی تمام فعالیتهایی است که منجر به تشخیص علل اصلی رخدادها و حل و فصل مشکلات میشود. همچنین، اجرایی شدن فرآیندهای حل و فصل رخداد را، از طریق روشهای کنترلیِ مقتضی، بهخصوص مدیریت تغییر، و مدیریت انتشار و استقرار پیگیری میکند.
در فرآیند مدیریت مشکل، تمام اطلاعات مرتبط با مشکلات و اقدامات مربوطه و راهحلها را ثبت و نگهداری
میشود. بنابراین، سازمانها میتوانند با استفاده از ابزارهایی مانند پایگاه داده خطای شناختهشده (Known Error Data Base: KEDB) از تعداد و اثرات رخدادها در طول زمان بکاهند. به همین علت هم در ابتدای مقاله اشاره کردیم که فرآیند مدیریت مشکل رابطهی تنگاتنگی با فرآیند مدیریت دانش دارد.
گرچه فرآیندهای مدیریت مشکل و مدیریت رخداد فرآیندهایی جداگانه هستند، شباهتهایی نیز دارند و حتی از ابزارهای یکسانی هم بهره میگیرند. مثلاً حتی ممکن است از طبقهبندی مشابه، سیستمهای اولویتبندی و اثرگذاری یکسانی استفاده کنند. چراکه این امر متضمن ارتباطاتی مؤثر در مواجهه با مشکلات و رخدادهای مرتبط خواهد شد.
وجه پیشگیرانه (Proactive) و واکنشی (Reactive) فرآیند مدیریت مشکل
هم فعالیتهای مدیریت واکنشی و هم فعالیتهای مدیریت پیشگیرانه، هر دو به دنبال یافتن مشکلات و مدیریت آنها با استفاده از فرآیندهای مدیریت مشکل، کشف علل اصلی رخدادهای مرتبط با آنها و جلوگیری از تکرار دوبارهی آنها هستند. وجه واکنشی یا همان انفعالی فرآیند مدیریت مشکل در راستای حل مشکلاتی است که مربوط به یک یا چند رخداد است. وجه پیشگیرانهی آن در راستای شناسایی و حل مشکلات و خطاهای شناختهشده است، قبل از آنکه دوباره رخدادهای مرتبط با آنها رخ دهد.
هنگامی که فعالیتهای مدیریت واکنشی، در پاسخ به وضعیت یک رخداد خاص در حال انجام است، فعالیتهای مدیریت پیشگیرانه برای فعالیتهای پیش رو برنامهریزی میکند تا دسترسی کلی و رضایت کاربر نهایی از خدمات IT را بهبود بخشد. تنها تفاوت میان مدیریت واکنشی و پیشگیرانه در چگونگی فرآیندهای این دو است.
مدیریت واکنشی
در مدیریت واکنشی، فعالیتهای فرآیندی غالباً در واکنش به یک رخداد انجام میشوند. مدیریت واکنشی مشکل، کاملکنندهی فعالیتهای مدیریت رخداد است که با تمرکز بر علل اساسی رخداد، از تکرار آن جلوگیری کرده و در صورت لزوم، راهحلها را شناسایی میکند.
مدیریت پیشگیرانه
در مدیریت پیشگیرانه مشکل، فعالیتهای فرآیندی در پی بهبود خدمات هستند. مانند فعالیتهای تحلیلی که برای یافتن علل اساسی رخدادهای قدیمی و برای جلوگیری از تکرار آنها انجام میشوند. مدیریت پیشگیرانه مشکل، کاملکنندهی فعالیتهای CSI است که با شناسایی مشکلات و بهبود اقدامات میتواند به افزایش کیفیت خدمت منجر شود.
یک مثال از فعالیتهای مدیریت پیشگیرانهی مشکلات، مرور متناوب و برنامهریزیشدهی اطلاعات رخدادهای قبلی، برای یافتن الگو، نشانه یا علامتی که حاکی از وجود خطایی اساسی در زیرساختها باشد. در ادامه، به بخشی از فعالیتهای پیشگیرانه در فرآیند مدیریت مشکل اشاره میکنیم:
- برنامهریزی برای بازبینیهای مکرر رخدادهای بزرگ میتواند به شناخت علت ریشهای مشکلات منجر شود و کمک کند که از وقوع مجدد آنها جلوگیری شود.
- بررسی فعالیتهای کاربری و سوابق تعمیرات و نگهداری، به صورت منظم و دورهای، میتواند منجر به شناسایی الگو یا روند فعالیتهایی شود که نشان از وجود یک مشکل ریشهای دارند.
- بازنگری رویدادهای ثبتشده، به صورت برنامهریزیشده و دورهای، با تمرکز بر الگوها و روند هشدارها و رویدادهای خاص که ممکن است نشاندهندهی یک مشکل ریشهای باشد.
- برنامهریزی برای جلسههای دورهای طوفان فکری (Brainstorming) که به ریشهیابی و شناسایی مشکلات ریشهای کمک میکنند.
- استفاده از برگههای چکلیست برای جمعآوری اطلاعات مشکلات خدمت یا کیفیت عملیات که میتواند منجر به شناسایی مشکلات ریشهای شود.
فعالیتهای مدیریت پیشگیرانه و واکنشی در فرآیند مدیریت مشکل، معمولاً در حیطهی عملکرد خدمات انجام میشوند. رابطهای نزدیک میان فعالیتهای مدیریت پیشگیرانهی مشکل و فعالیتهای چرخه عمر CSI وجود دارد که مستقیماً منجر به شناسایی و بهبود عملکرد خدمت خواهند شد. مدیریت پیشگیرانهی مشکل هر دوی این فعالیتها را از طریق تجزیه و تحلیل و هدفگذاری اقدامات پیشگیرانه پشتیبانی میکند. مشکلات شناساییشده، از طریق این فعالیتها، در CSI وارد شده تا در فرصتهای بهبود، مورد استفاده قرار گیرد.
مدلهای مشکلات
بسیاری از مشکلات منحصربهفرد هستند و هریک باید به روش خود مدیریت شوند. اما دور از ذهن نیست که بعضی رخدادها به دلیل وجود مشکلات ریشهای تکرار میشوند. (برای مثال، در جایی که هزینهی راهکار دائمی بالا باشد و تصمیم بر عدم عقد قراداد پرهزینه و سازش با مشکل باشد.)
مانند ایجاد یک خطای شناختهشده در KEDB، به منظور اطمینان از تشخیص سریعتر؛ ایجاد یک مدل مشکل در راستای مدیریت مشکلات مشابه در آینده نیز میتواند مفید باشد.
رخدادها و مشکلات
انقطاع برنامهریزینشده یک خدمت IT یا کاهش کیفیت آن، رخداد یا Incident نام دارد. مشکل، وجهه دیگری از رخداد را با نمایان کردن دلیل اساسی آن به نمایش میگذارد که ممکن است دلیل سایر رخدادها نیز باشد. رخدادها به مشکلات تبدیل نمیشوند. هنگامی که فعالیتهای مدیریت رخداد متمرکز بر بازگردان خدمت به حالت طبیعی است، فعالیتهای مدیریت مشکل بر یافتن راههای جلوگیری از وقوع رخداد از ابتدا متمرکز هستند. بسیار شایع است که رخدادهایی داشته باشیم که مشکل نیز هستند.
قوانین فراخوانی مدیریت مشکل در حین یک رخداد، میتواند متنوع و بسته به صلاحدید سازمانها باشد. برخی موقعیتهای عمومی که منجر به فراخوانی مدیریت مشکل در حین یک رخداد شود، میتواند بدین شرح باشد:
- مدیریت رخداد نمیتواند رخداد را با مشکلات موجود و خطاهای شناختهشده مرتبط کند.
- تجزیه و تحلیل رخدادهای ثبتشده، حاکی از وجود یک مشکل اساسی است.
- در جایی که فعالیتهای مدیریت مشکل برای شناسایی مشکل اصلی به کار بسته شده است، یک رخداد بزرگ اتفاق میافتد.
- سایر قابلیتهایITوجود یک مشکل را شناسایی میکنند.
- پیشخوان خدمت ممکن است یک رخداد را رفع کند، اما دلیل نهایی مشخص نشده و به نظر میرسد که رخداد در آینده تکرار شود.
- تجزیه و تحلیل تیم پشتیبانی از رخداد، نشان داده است که یک مشکل ریشهای وجود دارد، یا حداقل به نظر میرسد که وجود دارد.
- اخطار یک تأمینکننده مبنی بر وجود یک مشکل که باید برطرف شود.
روشهای تجزیه و تحلیل مشکل
روشها و تکنیکهای زیادی برای آنالیز، تشخیص و رفع مشکل وجود دارد و تحقیقات زیادی نیز در این زمینه انجام شده است. در ادامه، چند نمونه از تکنیکهایی را که کاربرد بیشتری دارند بررسی کردهایم.
تحلیل بر مبنای ترتیب وقوع (Chronological Analysis)
هنگام وقوع یک مشکل دشوار، ممکن است با گزارشهای متناقضی در مورد زمان و چگونگی اتفاق مواجه شویم. بنابراین، تهیهی یک جدول زمانی خلاصه از رویدادها بسیار مفید خواهد بود. با در اختیار داشتن این زمانبندی، میتوانیم تشخیص دهیم که چه رویدادی در پی رویدادهای دیگر رخ داده یا کدام اتفاق ارتباطی با سایرین ندارد.
تحلیل ارزش مشکل (Pain Value Analysis)
در اینجا، یک دید کلی از اثرات رخداد یا مشکل به دست میآوریم. با آنالیز تعداد رخداد یا مشکلهایی با نوع خاص که در یک زمان خاص رخ داده است، میتوانیم درک بهتر و دقیقتری از سطح اثرات بهجا مانده از رخداد یا مشکل بر بدنهی سازمان یا کسب و کار بهدست آوریم. میتوان فرمولی را برای محاسبهی عمق فاجعه تبیین کرد که میتواند شامل موارد زیر باشد:
- تعداد افرادی که تحت تأثیر قرار گرفتهاند.
- مدت زمانی که باعث قطعی شده است.
- هزینهای که برای سازمان به بار آمده است (اگر قابل محاسبه یا تخمین است).
با محاسبهی تمام فاکتورهای بالا، جزئیات بیشتری از عمق فاجعه به دست خواهید آورد.
روش آنالیز کپنر و تریگو (Kepner and Tregoe)
کارلوس کپنر و بنجامین تریگو راهی برای آنالیز مشکل طراحی کردهاند که میتواند برای بررسی مشکلات پایهای و اصلی مورد استفاده قرار گیرد. روش آنها شامل مراحل زیر است:
- تعریف مشکل
- توصیف مشکل از منظر مکان، زمان و ابعاد
- در نظر گرفتن علل احتمالی
- بررسی علتهای متداولتر
- بررسی و تأیید علت اصلی
طوفان فکری (Brainstorming)
خیلی از اوقات گردهم آمدن افراد مرتبط با مشکل، چه به صورت فیزیکی و چه از طریق ابزارهای آنلاین و طوفان فکری در رابطه با مشکل، بسیار مفید و کارساز خواهد بود. در این نشست، افراد دلایل و نیز راهحلهای محتمل را به بحث و گفتوگو میگذارند. این جلسات میتواند بسیار سازنده و نوآورانه باشد، اما بیشک حضور فردی مانند مدیر مشکل، ضروری است تا کنترلی روی جلسه داشته و تمامی خروجیهای آن را نیز مستند کند.
پنج چرا (5-Whys)
این راه بسیار ساده و در عین حال بسیار سودمند است تا دلیل اصلی مشکل را بیابیم. کار بدین صورت است که از تشریح رویدادی که اتفاق افتاده آغاز شده و سپس پرسش «چرا این اتفاق افتاد؟» مطرح میشود. پاسخ دریافت میشود و در مرحلهی بعد باز هم پرسش «چرا این اتفاق افتاد؟» مطرح میشود. معمولاً در پنجمین بار، دلیل اصلی پیدا میشود!
محصور کردن عامل مشکل (Fault Isolation)
این روش در مواجهه با تراکنشها یا رویدادهایی است که میتوانند به مشکل ختم شوند. به صورت قدم به قدم، هر مرتبه یک CI را بررسی کرده تا CI مقصر شناسایی شود. تلاش ما از اولین CI مرتبط با معامله یا رویداد آغاز شده و تا آخرین CI ادامه مییابد تا مقصر پیدا شود. اگر مقصر پیدا نشد، مدل دیگری از این روش میتواند مورد استفاده قرار بگیرد که شامل سنجش صحت CIهای مرتبط با معامله یا رویداد است. برای مثال، اگر یک CI به عنوان مقصر فرض شد، باید صحت تمامCI های دیگر که مرتبط با آن معامله یا رویداد هستند، ارزیابی شود.
تهیهی نقشهی وابستگیها (Affinity Mapping)
این روش برای سازماندهی دادههای وسیع (ایدهها، نظرات، مسائل) در گروههایی با ویژگیهای مشترک استفاده میشود که معمولاً در جلسات طوفان فکری، با اعضای کلیدی پشتیبانی، انجام میشود. موضوعات کلیدی مانند راهحلهای بالقوه، توسط هر فرد روی کارتهایی نوشته و روی دیوار یا تخته وایتبرد الصاق میشود. سپس با مشارکت همگی، کارتها جابهجا شده و در گروههایی با صفات مشترک، تقسیم میشوند. سپس، برای هر گروه، یک نام انتخاب میشود.
دقت کنیم که هرکدام از کارتهایی که در یک گروه قرار دارند، مورد ارزیابی قرار میگیرد که شاید معلول علتی باشد که مسبب تمامِ اعضای گروه است.
آزمون فرضیه (Hypothesis Testing)
در این روش، فهرستی از علتهای ریشهایِ احتمالی، بر مبنای حدسیات علمی، تهیه میشود. سپس، درستی یا نادرستی هر یک بررسی خواهد شد. حدسیات علمی ممکن است بر اساس روابط میان متغیرها یا دلایل ریشهایِ بالقوهی مشکلات باشد. با استفاده از اطلاعات جمعآوریشده از رخدادها و سایر عملیات، تیمی برای طوفان فکری به همراه فهرستی از دلایل بالقوه که ممکن است علت رخدادها باشند، گردهم میآیند. سپس، هر دلیل به یک فرضیه بدل شده و به یکی از اعضای تیم پشتیبانی جهت بررسی، ارجاع داده میشود. در انتها، دادههای مورد نیاز جمعآوری میشوند و هر فرد، فرضیهی خود را تأیید یا رد میکند.
پست نظارت فنی (Technical Observation Post)
در برخی موارد، مشکلات به رخدادهایی متصل هستند که به دلایل نامعلوم مدام تکرار میشوند. برای مقابله با این وضعیت، تیمی از متخصصان پشتیبانی از بخش IT سازمان گردهم میآیند تا تمام رویدادها را به صورت زنده رصد کنند تا وضعیت خاص و دلایل احتمالی یک مشکل را شناسایی کنند.
نمودارهای ایشیکاوا (Ishikawa Diagrams)
کااورو ایشیکاوا (1915 – 1989) پدر علم کنترل کیفیت ژاپن، روشی را برای مستندسازی دلایل و تأثیرات ابداع کرده است که در شناسایی کارکرد اشتباه عضوی از سیستم، یا نیاز به ارتقای آن، میتواند مفید باشد. این نمودار خروجی یک جلسهی طوفان فکری، متشکل از متخصصان حل مشکل و پیشنهادهای آنها خواهد بود. هدف اصلی در قالب تنهی یک نمودار و عوامل اولیه روی شاخههای آن نمایش داده میشود.
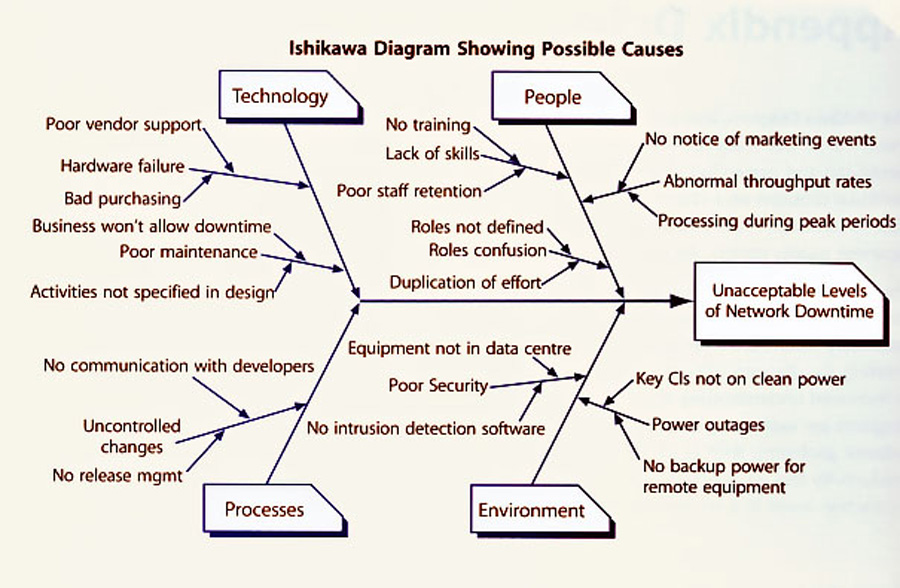
سپس، عوامل ثانویه به شکل ساقهها اضافه میشوند و به همین ترتیب پیش میرود. ساخت چنین نموداری، موجب تحریک مباحثهها شده و معمولاً منجر به افزایش آگاهی نسبت به کلیت مشکل میشود.
تحلیلهای پارِتو (Pareto Analysis)
این روش، برای جداسازی مهمترین دلایل بالقوهی مشکلات از موارد بیاهمیت است.
در جدول زیر، موقعیتهای مختلف و روشهای مفید در هر کدام، دستهبندی شده است.
وضعیت مشکلها و مفیدترین روشهای شناسایی دلایل اصلی
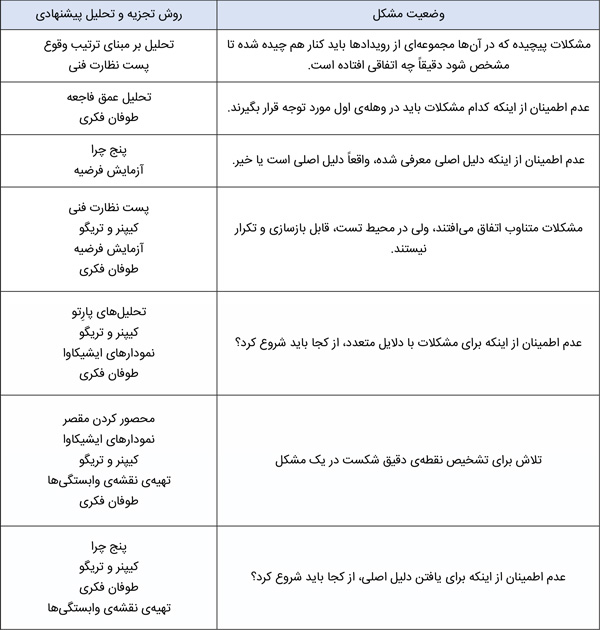
شناسایی خطاها در محیط برنامهنویسی
بسیار کم اتفاق میافتد که برنامه، اپلیکیشن یا سیستمی منتشر شود و کاملاً بدون خطا باشد. اغلب در هنگام انتشار این برنامهها، از یک سیستم اولویتدهی استفاده میشود تا خطاهای بسیار مهم از بین بروند. ولی خطاهای کوچک معمولاً باقی میمانند. البته دلیل این امر، برآورده ساختن نیازهای کسب و کار در انتشار هرچه سریعتر قابلیتها و نسخههای جدید و نیز اطمینان از بدون خطا بودن کدها و اجزاست.
هنگامیکه تصمیم گرفته میشود چیزی در یک محیط زنده آزمایش بشود، باید خطاهای شناختهشده را نیز، همراه با جزئیات دقیقی از اقدامات و راهحلها، در KEDB وارد کرد. پیشنهاد میکنیم برای این کار، یک مرحلهی رسمی تبیین کنید تا مطمئن شوید که هیچوقت از قلم نمیافتد.
تجربه نشان داده که اگر این اقدامات انجام نشود و کاربران شروع به استفاده و شناسایی خطاها و ثبت رخداد نکنند، هزینههای گزافی در ادامه خواهد آمد و یک چرخهی رفع خطا و بهروزرسانیهای طولانی آغاز خواهد شد.
مزایای فرآیند مدیریت مشکل برای کسب و کار
اگر بخواهیم از مزایای فرآیند مدیریت مشکل حرف بزنیم باید یک مقالهی دیگر را به این موضوع اختصاص بدهیم! چون تا همینجا بر همه روشن شده که این فرآیند مزایای بیشماری دارد که بر همهی ارکان کسب و کار تأثیر میگذارد و میتواند روی افزایش سودآوری، افزایش رضایت کاربران و مشتریان، صرفهجویی در هزینهها و بهبود خدمات تأثیر مستقیم بگذارد. اما در اینجا، چون مجال پرداختن به همهی جزئیات نیست، به برخی از مزایای این فرآیند در اداکه میپردازیم و در مقالهی بعدی، جزئیات بیشتری در مورد روشها و تکنیکهای این فرآیند را با یکدیگر پیش خواهیم برد.
- دسترسی هرچه بیشتر به خدمات فناوری اطلاعات، با کاهش تعداد و مدت زمان رخدادهایی که ممکن است آن خدمات را درگیر کنند. فرآیند مدیریت مشکل به صورت همزمان با فرآیندهای مدیریت رخداد و مدیریت تغییر کار میکند تا افزایش کیفیت و دسترسی خدمات IT را برای مشتریان و کاربران فراهم کند. هنگامی که رخدادها رفع میشوند، اطلاعات مربوطه ذخیره میشود. با گذشت زمان، این اطلاعات برای سرعتبخشی به حل و شناسایی راهحلهای اساسی و نیز کاهش تعداد و زمان تشخیص، مورد استفاده قرار میگیرد.
- افزایش بهرهوری و توانمندی IT، با کاهش فعالیتهای ناخواستهی ناشی از رخدادها و افزایش سرعت حلوفصل رخدادها با ذخیره اطلاعات خطاهای شناختهشده و فعالیتهای مربوط به آن.
- کاهش هدررفت انرژی ناشی از فعالیتهای غیرکارآمد
- کاهش هزینههای ناشی از تلاش مستمر در راستای حل رخدادهای تکراری