
 زمان تقریبی مطالعه: 7 دقیقه
زمان تقریبی مطالعه: 7 دقیقهمدیریت رخداد از منظر ITIL
در ITIL، به هر اختلال یا وقفهای در عملکرد خدمت که ممکن است به اختلال در خدمت یا افت کیفیت آن منجر شود، رخداد (Incident) گفته میشود. موارد خطا و خرابیِ مؤلفه های خدمت که ممکن است در آینده به اختلال خدمت منجر شوند نیز رخداد تلقی می شوند. به مدیریت چرخه عمر رخدادها، از زمان اعلام یا شناسایی تا خاتمهی آن، به نحوی که رخداد به سرعت حل و فصل شده و خدمت متأثر از آن بازیابی شود، نیز مدیریت رخداد میگویند.
حل و فصل رخداد معادل واژهی Resolve است. هدف از حل و فصل رخداد، یافتن خطای نهفتهای نیست که منجر به وقوع رخداد شده، بلکه هدف آن است که به هر طریقی، حتی به کمک یک روش موقت، خدمت به سرعت بازیابی شود.
هر شخصی که به نوعی با خدمت در ارتباط است، میتواند اعلامکنندهی یک رخداد باشد، مانند کاربران، از طریق ابزارهای پایش، یا متخصصین فنی و…
در سازمانها، در فرآیند مدیریت رخداد، معمولاً واحد کارکردی پیشخوان خدمت وظیفهی مدیریت و پاسخگویی به رخدادها را برعهده دارد.
ارزش مدیریت رخداد برای کسب و کار
در فرآیند مدیریت رخداد، رویکردی فرآیندگرا در حوزه ای که سازمان با مشتریان در ارتباط است، استقرار مییابد. ازاینروست که استقرار این فرآیند در هر سازمان یا شرکت ارائه دهندهی خدمت، خیلی زود از طرف فضای کسب و کار و مشتریان درک شده و به اصطلاح به چشم می آید. بنابراین، ارزش مدیریت اثربخش رخداد برای واحدهای کسب و کار، در مقایسه با سایر حوزههای عملیات خدمت، سادهتر و سریعتر نمود پیدا میکند و به همین علت است که بیشتر پروژههای استقرار مدیریت خدمات فناوری اطلاعات (ITSM) با این فرآیند آغاز میشوند.
یکی از مزایای شروع پروژهی استقرار مدیریت خدمات فناوری اطلاعات با فرآیند مدیریت رخداد این است که، در نتیجهی استقرار این فرآیند، مشخص میشود که عملکرد کدامیک از حوزه ها و فرآیندهای دیگر سازمان، نیازمند بهبود است. این یکی از عللی است که مدیران فناوری اطلاعات هرگز به فرآیند مدیریت رخداد نه نمیگویند. در ادامه بر برخی از دیگر ارزشهای مدیریت رخداد برای کسب و کارها اشاره میکنیم.
- توانایی تشخیص و حل و فصل رخدادها به کاهش زمان خرابی (Downtime) سیستم در کسب و کارها میانجامد. به بیان دیگر، با تشخیص رخداد و حل و فصل آن در اسرع وقت، زمان فعال بودن سیستم یا به اصطلاح آپ بودن (UP) آن افزایش مییابد. بیشتر شدن زمان فعالیت سیستم، افزایش قابلیت اطمینان (Reliability) و در نتیجه افزایش دسترسپذیری (Availability) را در پِی خواهد داشت.
- اطلاعات بسیاری که از بررسی روند رخدادها به دست میآید، به مدیریت فناوری اطلاعات در شناسایی اولویتهای کسبوکار، تخصیص منابع به شکلی پویا و متناسب با نیازمندیها، و در نهایت همسویی فناوری اطلاعات با اولویتهای کسب و کار کمک میکند.
- تشخیص اقلام پیکربندی مرتبط با هر رخداد و ریشه یابی رخدادها، امکان شناسایی آن خدمات و داراییهایی را که بیشتر در معرض اختلال بودهاند یا عوامل کلیدی مسبب بروز یک رخداد را فراهم میکند. این امر منجر به شناسایی زمینههای بهبود هر خدمت خواهد شد.
- پیشخوان خدمت در حین رسیدگی به رخدادها، میتواند نیازمندیهای آموزشی، مهارتی، نرمافزاری، سختافزاری، زیرساختی و… را شناسایی کند.
بهرهگیری از مدل رخدادها تکرارپذیری رویهی رسیدگی به رخدادهای مختلف را بالا میبرد. چنانچه این تکرارپذیری خودکارسازی نشود، میتواند به یک بروکراسی آزاردهنده بیانجامد. بنابراین، پیشنهاد میشود که مدلهای رخداد را، با بهرهگیری از ابزارهای مناسب خودکارسازی کنید.
مدلهای رخداد
بسیاری از رخدادها تکراری هستند. یعنی قبلاً اتفاق افتادهاند و به احتمال فراوان دوباره هم اتفاق میافتند. به همین علت، بسیاری از سازمانها میتوانند رخدادها را در قالب مدلهای استاندارد دستهبندی کرده و برای حل و فصل، آنها را به صورت رویههای از پیش تعیینشده طرح ریزی نمایند.
مدل رخداد روشی از پیش تعریفشده، شامل اقدامات لازم برای رسیدگی به یک نوع خاصِ رخداد است که تمامی ذینفعان بر انجام آن توافق دارند.
خودکارسازی مدل رخدادها، از طریق ابزارهای مدیریت خدمات، ضامن رسیدگی به رخداد مطابق روش توافقشده و بر اساس محدودیتهای زمانی تعیینشده خواهد بود.
موارد زیر باید در مدل رخداد مشخص شوند:
- مراحل طیشده برای مدیریت یک رخداد، از زمان شناسایی تا زمان حل و فصل آن؛
- زمانبندی و وابستگی بین مراحل (تقدم و تأخر)؛
- اقدامات لازمالاجرا، پیش از رسیدگی به یک رخداد؛
- نقشها، اختیارات و مسئولیتها و ارتباط آنها با مراحل رسیدگی به رخداد؛
- بازههای زمانی و آستانهها (Thresholds)، برای تکمیل فعالیتهای مراحل مختلف؛
- رویههای ارجاع به سطوح بعدی (Escalation) که مشخص میکند یک رخداد در چه شرایطی باید به سطوح بعد ارجاع داده شود و چه کسی، در سطوح بعدی، پاسخگوی این رخداد خواهد بود؛
- کارهای لازم برای فراهم آوردنِ دلایل و شواهد بروز یک رخداد.
جریان کاری در فرآیند مدیریت رخداد
در شکل زیر میتوانید جریان کاری فرآیند مدیریت رخداد را مشاهده کنید. هریک فعالیتهای این فرآیند را در ادامه، به تفصیل، بررسی خواهیم کرد.
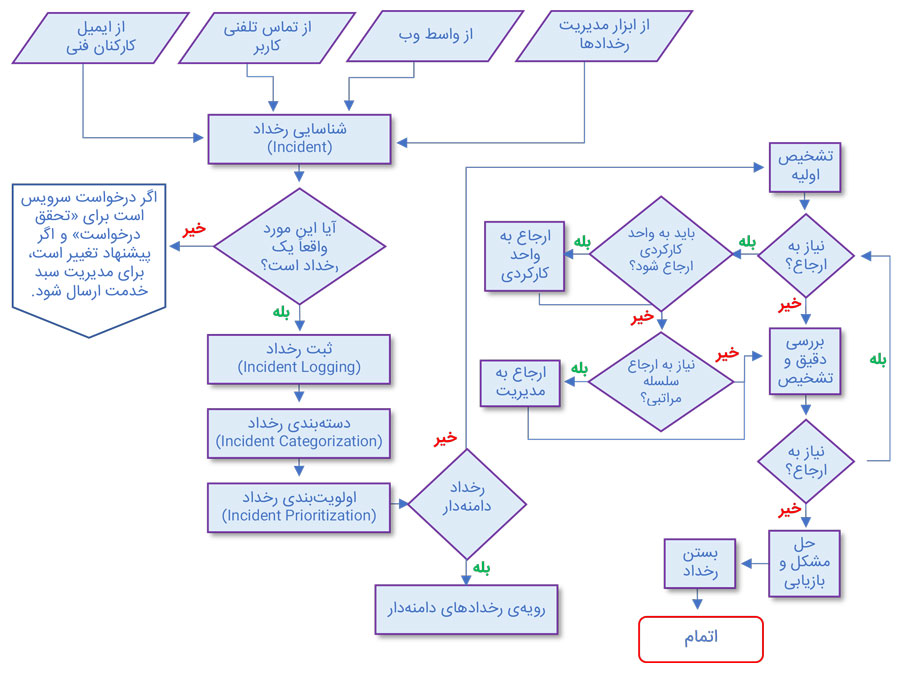
ثبت رخداد مقوله ای مهم است که برخی از سازمانها به ارزش واقعی آن واقف نیستند، چراکه این مهم نهتنها به شکلگیری یک پایگاه دانش، برای پیگیری و بهبود عملکرد فرآیند مرتبط کمک میکند، بلکه به پیگیری و بهبود دیگر فرآیندهای سازمان هم کمک کرده و برای آنها ارزشآفرینی میکند.
1- شناسایی رخداد (Incident Identification)
فرآیند مدیریت رخداد با شناسایی رخداد آغاز میشود. تا رخدادی شناسایی نشود، مراحل بررسی و حل و فصل آن آغاز نخواهد شد. اگر چه یکی از راههای شناسایی رخداد، اعلام آن توسط کاربرانِ خدمت موردنظر است، اما این تنها راه شناسایی نیست و سازمان ارائهدهنده خدمات همواره درصدد است که رخدادها را، پیش از آنکه بر استفادهکنندهی خدمت تأثیر بگذارد، شناسایی و حل و فصل کند.
2- ثبت رخداد (Incident Logging)
لازم است اطلاعات هر رخداد، جدای از روش شناسایی آن، ثبت شود. این اطلاعات، علاوه بر مشخصات شناسایی رخداد، شامل مواردی است که به حل و فصل سریعتر رخداد کمک میکند.
3- دستهبندی رخداد (Incident Categorization)
دستهبندی رخدادها شناسایی موارد تکراری را آسانتر میکند. همچنین، سبب میشود تحلیل روند رخدادها به صورت مؤثر انجام شود. اطلاعات دستهبندی رخدادها از جمله اطلاعاتی است که باید در همان ابتدا ثبت شود. اما چون دستهبندیها در ابتدای استقرار فرآیند مدیریت رخداد در هر سازمان، شناسایی و تعریف میشوند، ممکن است این دستهبندیها با ایراداتی همراه باشند. به مرور زمان و با کسب تجربیات در پیشخوان خدمت، دستهها بازنگری شده و مجموعهی مناسبی از آنها ایجاد میشوند. یعنی اگر دستهای که در مراحل اولیه ثبت شده، در مراحل حل و فصل مشخص شود که اشتباه بوده، این دستهبندی اصلاح میشود.
از آنجا که رخدادهای تکرارپذیر یکی از ورودیهای مدیریت مشکل هستند، شناسایی رخدادهای تکراری و تحلیل آنها به مدیریت مؤثرتر مشکلات میانجامد.
4- اولویتبندی رخداد (Incident Prioritization)
اولویت معمولاً از ترکیب دو عامل «میزان فوریت حل و فصل رخداد» (Urgency) و «دامنهی تأثیرات آن» (Impact) مشخص میشود. میزان فوریت و دامنهی تأثیرات رخداد باید، در زمان ثبت آن، مشخص و ثبت شوند.
در هر سازمان، غالباً برای شناسایی فوریت و تشخیص دامنهی تأثیرات رخدادها، دستورالعملی تهیه شده و در اختیار پیشخوان خدمت قرار میگیرد. پس از ثبت فوریت و دامنهی تأثیرات رخداد توسط پیشخوان خدمت، اولویت رخداد به صورت خودکار بر اساس این دو عامل محاسبه و تعیین میشود.
تعیین خودکار اولویت رخداد در حالتی امکانپذیر است که روش از پیش تعریفشده ای برای تعیین اولویت، بر اساس مقادیر فوریت و دامنهی تأثیرات، وجود داشته باشد. اولویت رخداد ممکن است در طول عمر آن، به صورت خودکار و بر اساس رویه های از پیش تعریفشده (مثلاً افزایش اولویت با سپری شدن زمان عدم حل و فصل رخداد) یا به صورت دستی و به تشخیص پیشخوان خدمت تغییر کند.
5- تشخیص اولیه (Initial Diagnosis)
پس از اعلام رخداد به پیشخوان خدمت، لازم است در اسرع وقت، علت وقوع و راهکار حل و فصل رخداد مشخص شود. پایگاه اطلاعات خطاهای شناسایی شده و اسکریپتهایی که به منظور شناسایی علل رخداد و انجام اقدامات تشخیصی وضعیت سیستم در زمان بروز رخداد، در اختیار پیشخوان قرار میگیرد میتواند در این تشخیص اولیه کمککننده باشد.
در رخدادهایی که به صورت تلفنی به پیشخوان اعلام میشود، معمولاً زمان تشخیص اولیه به اندازهی یک مکالمهی تلفنی است. در واقع، فرد پاسخگو در پیشخوان سعی میکند با توجه به دانش خود و اطلاعات در دسترس، راهکار حل و فصل رخداد را تشخیص دهد. در صورتی که او، برای حل و فصل رخداد، به زمان بیشتری نیاز داشته یا راهکاری نداشته باشد، تشخیص راهکار به مراحل بعدی موکول میشود.
6- ارجاع به سطوح بعدی (Incident Escalation)
در صورتی که سطح پاسخگو به رخداد نتواند رخداد را حل و فصل کند یا، بر اساس دستورالعمل، زمان مجاز برای حل و فصل رخداد در این سطح خاتمه یابد، رخداد به سطوح بعدی ارجاع داده میشود. سطوح بعدی، بر اساس کارکرد یا سلسلهمراتب سازمانی، درگیر حل و فصل رخداد میشوند.
ارجاع بر اساس کارکرد در شرایطی است که نیاز به تبحر و دانش بیشتری در زمینهی موضوع رخداد باشد. مثلاً فرض کنید که شبکه اطلاعاتی قطع شده و سطح اول پیشخوان خدمت قادر به شناسایی علل وقوع رخداد یا حل و فصل آن نیست، در این شرایط، رخداد فوق به گروه عملیات شبکه ارجاع داده میشود.
ارجاع بر اساس سطوح سازمانی در شرایطی است که، برای حل و فصل یک رخداد، به مجوز یا دسترسی به منابع بیشتری نیاز باشد. در این حالت، لازم است که مدیر فرد پاسخگو یا مدیران ارشد از موضوع رخداد مطلع شده تا بتوانند برای تخصیص منابع بیشتر یا تفویض اختیارات اقدامات لازم را انجام دهند.
7- بررسی و تشخیص (Investigation and Diagnosis)
رخدادی که گزارش شده، ممکن است توسط سطوح مختلف بررسی شده و هر سطح، در زمینه بازتولید، تشخیص علت وقوع و همچنین حل و فصل آن اقداماتی انجام دهند. لازم است جزئیات این اقدامات و نتایج مشاهدهشده پس از هر اقدام، در مورد هر رخداد، ثبت شود. این جزئیات برای تشخیص راهکار نهاییِ حل و فصل رخداد راهگشا خواهند بود. تعریف سطوح پاسخگویی و مدت زمان مجازِ هر سطح برای رسیدگی به رخداد، میتواند در جلوگیری از اتلاف زمان در ارائهی راهکار نهایی مؤثر باشد.
8- حل و فصل رخداد و بازیابی خدمات (Resolution and Recovery)
هنگامی که راهکار محتمل برای حل و فصل رخداد تشخیص داده شد، باید اعمال شده و برای اطمینان از صحت عملکرد آن، راهکار فوق باید آزموده شود. برای این منظور، ممکن است فرد پاسخگو در پیشخوان خدمت از راه دور اقدام کند، از گروه عملیات کمک بگیرد یا از کاربر متأثرشده از رخداد بخواهد که راهکار موردنظر را اِعمال و نتیجه را اعلام کند.
9- خاتمه رخداد (Incident Closure)
پیشخوان خدمت در نهایت باید از حل و فصل رخداد موردنظر و رضایت کاربر اطمینان حاصل کند. پس از آن، رخداد با توافق کاربر خاتمه مییابد. لازم است که، پیش از خاتمه، پیشخوان خدمت موارد زیر را بررسی کرده و مطمئن شود که همگی محقق شده باشند.
- کسب اطمینان از صحت دستهبندی اولیهی رخداد و اصلاح و به روزرسانی آن در صورت نیاز؛
- ارزیابی رضایت کاربر، از راه تماس تلفنی و یا ارسال ایمیل، برای کسب اطمینان از حل و فصل رخداد و نبود پیامدهای احتمالی؛
- تکمیل اطلاعات و مستندات مرتبط با رخداد، به نحوی که جزئیات مورد نیاز و تاریخچهی اقداماتِ صورتگرفته، برای رخدادهای احتمالیِ بعدی، به شکل مناسبی در دسترس باشد؛
- بررسی امکان تکرار رخداد و اقدامات پیشگیرانهای که میتواند از وقوع دوبارهی آن جلوگیری کند. این موارد ممکن است منجر به ثبت یک مشکل یا تغییر در سیستم شده که در این موارد، اقدامات لازم در فرآیند مدیریت مشکل یا مدیریت تغییر پِی گرفته میشود.
منبع: برگرفته از ITIL Service Operation – 2011 Edition